

Este componente permite analizar texto para transcribir un resumen y también puede analizar imágenes con el fin de dar un reporte de lo que se observó en la imagen.
Se encuentra dentro del grupo de componentes llamado “Cognitivos” y está disponible para los routing points de tipo interaction, chat y crm + webhook.
Sintaxis #
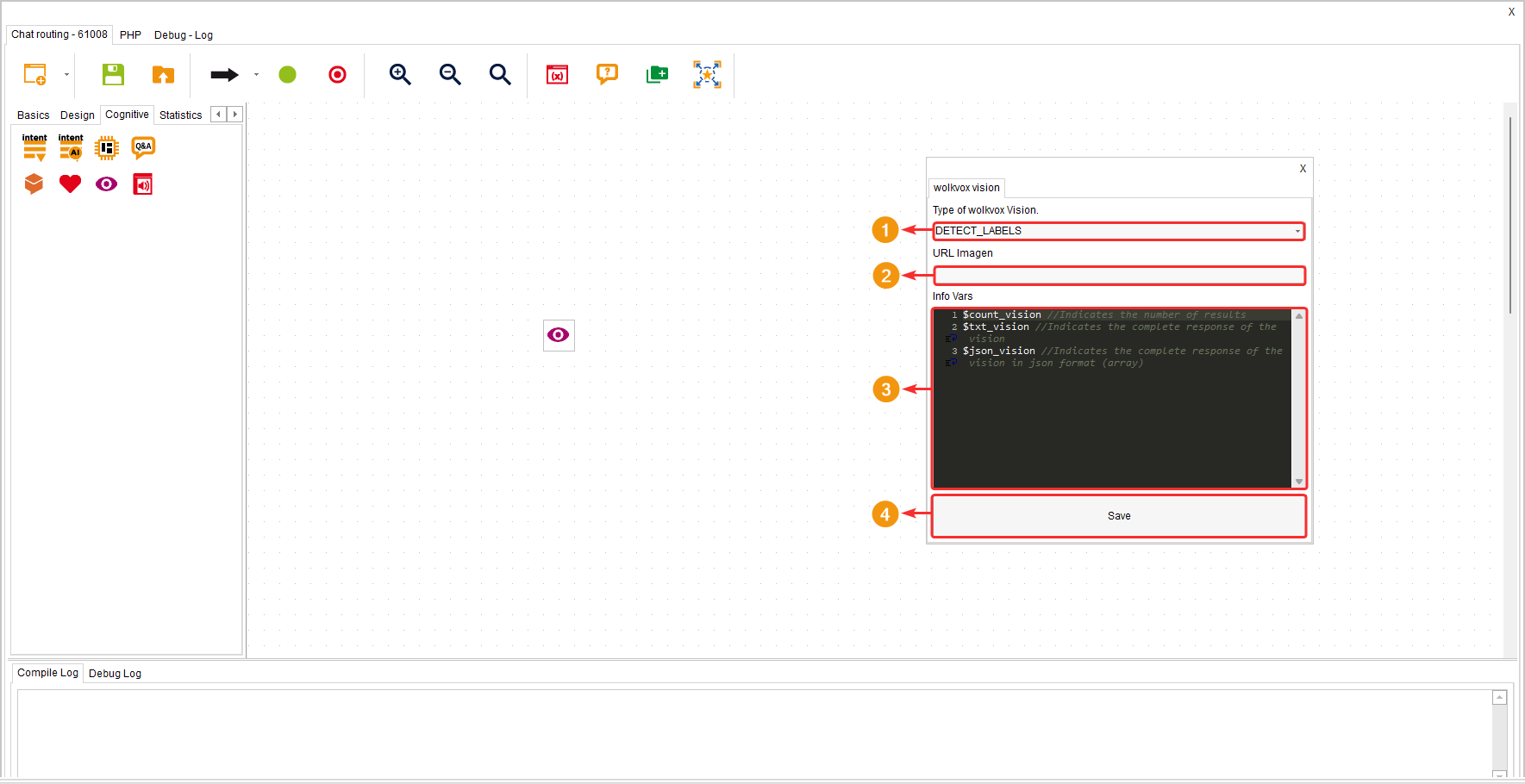
- Selecciona el tipo de análisis que deseas obtener. Esta característica del componente permite realizar análisis específicos de imágenes utilizando la Inteligencia Artificial del componente “Visión”. Cada opción se enfoca en un tipo diferente de análisis, lo que permite obtener información valiosa de las imágenes y mejorar la interacción con los clientes de una manera más dinámica y eficiente.
- Detect_labels: Esta opción permite detectar etiquetas o categorías que describen los objetos o elementos presentes en una imagen. Por ejemplo, si una imagen contiene un automóvil, una persona y un edificio, esta función podría detectar y etiquetar esos elementos.
- Detect_text: Con esta opción, el componente es capaz de detectar y extraer el texto presente en una imagen. Es especialmente útil para leer texto escrito a mano, textos en letreros o cualquier otro contenido de texto dentro de una imagen.
- Detect_faces: Esta opción permite detectar rostros en una imagen y proporcionar información adicional sobre ellos, como la posición del rostro en la imagen y características como la edad y el género estimados.
- Object_localization: Con esta opción, el componente puede localizar objetos específicos en una imagen y proporcionar información sobre su ubicación exacta en la imagen, permitiendo la identificación precisa de elementos dentro de la imagen.
- Text_detection: Similar a “Detect_text”, esta opción se enfoca en detectar y extraer texto de una imagen, pero puede ser más avanzada al proporcionar información adicional sobre la estructura del texto, como su diseño y formato.
- Escribe la variable o URL (pública) de la imagen donde se encuentra almacenada la imagen que se va a analizar.
- Puedes ver las variables disponibles del componente para obtener los resultados.
- $count_vision: En esta variable se guarda el número de resultados obtenidos en el análisis.
- $txt_vision: En esta variable se guarda toda la respuesta del componente en su análisis.
- $json_vision: En esta variable se guarda (en formato JSON) toda la respuesta del componente en su análisis.
- Haz clic en “Guardar” para aplicar los cambios.
Funcionalidad “Total_vision” #
- Esta funcionalidad permite realizar un análisis muy avanzado de imágenes y obtener una respuesta de la inteligencia artificial con un alto nivel de confiabilidad.
- Recuerda que este componente solo está disponible en los routing points de tipo “ChatBot”, “Interaction routing” y “CRM + Webhook + Cron + AutoQAi + Mr Wizard” y se encuentra dentro del grupo de componentes llamado “Cognitivos”.
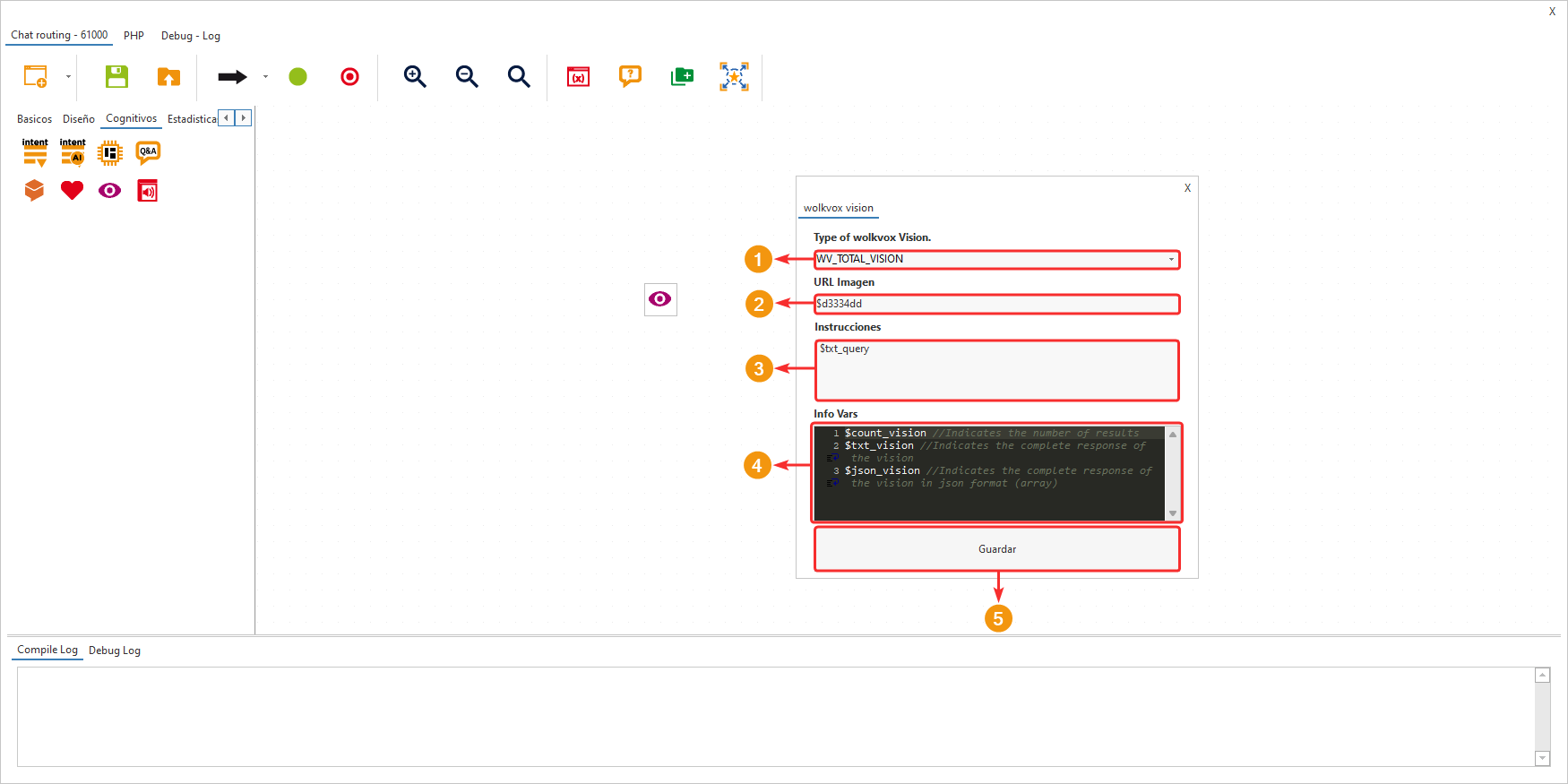
- En “Type of wolkvox Vision” selecciona la opción “WV_TOTAL_VISION”.
- En “URL Imagen” escribe la variable que contiene la imagen que deseas analizar.
- En “Instrucciones” escribe la instrucción que le deseas hacer a la inteligencia artificial para que la procese una vez analice la imagen. Puedes escribir la variable “txt_query” para que la inteligencia artificial tenga en cuenta la instrucción enviada por el cliente en un mensaje.
- Las “Info Vars” permiten obtener los resultados del análisis hecho por la inteligencia artificial. $txt_vision permite obtener el texto de la respuesta de la inteligencia artificial.
- Da clic en “Guardar” para aplicar la configuración del componente.
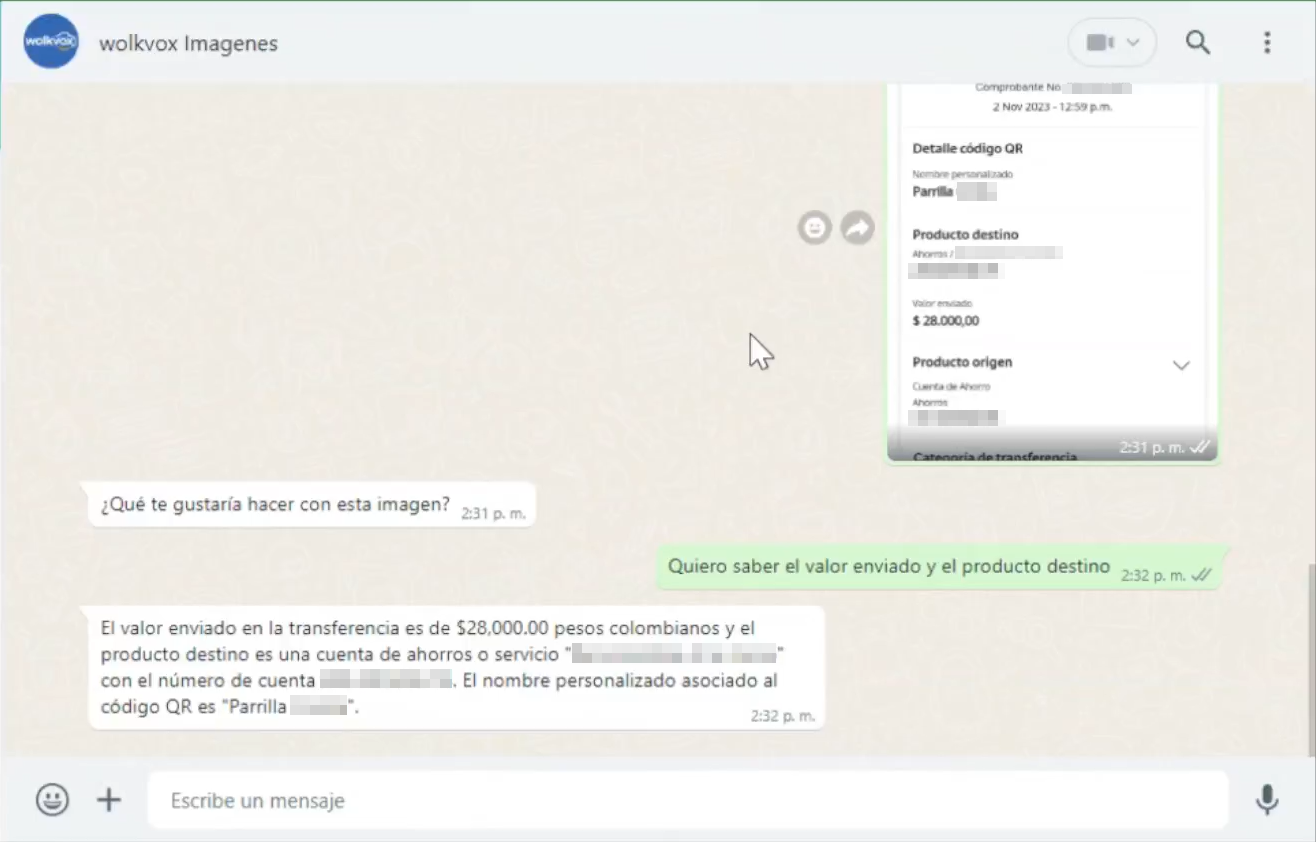
En la siguiente imagen se puede observar un ejemplo de la respuesta que obtendría un cliente si tenemos en el flujo, el uso del componente “Vision” con la nueva funcionalidad “Total Vision” configurado para hacer un análisis según la instrucción del cliente.

Este componente permite analizar texto para transcribir un resumen y también puede analizar imágenes con el fin de dar un reporte de lo que se observó en la imagen.
Se encuentra dentro del grupo de componentes llamado “Cognitivos” y está disponible para los routing points de tipo interaction, chat y crm + webhook.
Sintaxis #
- Selecciona el tipo de análisis que deseas obtener. Esta característica del componente permite realizar análisis específicos de imágenes utilizando la Inteligencia Artificial del componente “Visión”. Cada opción se enfoca en un tipo diferente de análisis, lo que permite obtener información valiosa de las imágenes y mejorar la interacción con los clientes de una manera más dinámica y eficiente.
- Detect_labels: Esta opción permite detectar etiquetas o categorías que describen los objetos o elementos presentes en una imagen. Por ejemplo, si una imagen contiene un automóvil, una persona y un edificio, esta función podría detectar y etiquetar esos elementos.
- Detect_text: Con esta opción, el componente es capaz de detectar y extraer el texto presente en una imagen. Es especialmente útil para leer texto escrito a mano, textos en letreros o cualquier otro contenido de texto dentro de una imagen.
- Detect_faces: Esta opción permite detectar rostros en una imagen y proporcionar información adicional sobre ellos, como la posición del rostro en la imagen y características como la edad y el género estimados.
- Object_localization: Con esta opción, el componente puede localizar objetos específicos en una imagen y proporcionar información sobre su ubicación exacta en la imagen, permitiendo la identificación precisa de elementos dentro de la imagen.
- Text_detection: Similar a “Detect_text”, esta opción se enfoca en detectar y extraer texto de una imagen, pero puede ser más avanzada al proporcionar información adicional sobre la estructura del texto, como su diseño y formato.
- Escribe la variable o URL (pública) de la imagen donde se encuentra almacenada la imagen que se va a analizar.
- Puedes ver las variables disponibles del componente para obtener los resultados.
- $count_vision: En esta variable se guarda el número de resultados obtenidos en el análisis.
- $txt_vision: En esta variable se guarda toda la respuesta del componente en su análisis.
- $json_vision: En esta variable se guarda (en formato JSON) toda la respuesta del componente en su análisis.
- Haz clic en “Guardar” para aplicar los cambios.
Funcionalidad “Total_vision” #
- Esta funcionalidad permite realizar un análisis muy avanzado de imágenes y obtener una respuesta de la inteligencia artificial con un alto nivel de confiabilidad.
- Recuerda que este componente solo está disponible en los routing points de tipo “ChatBot”, “Interaction routing” y “CRM + Webhook + Cron + AutoQAi + Mr Wizard” y se encuentra dentro del grupo de componentes llamado “Cognitivos”.
- En “Type of wolkvox Vision” selecciona la opción “WV_TOTAL_VISION”.
- En “URL Imagen” escribe la variable que contiene la imagen que deseas analizar.
- En “Instrucciones” escribe la instrucción que le deseas hacer a la inteligencia artificial para que la procese una vez analice la imagen. Puedes escribir la variable “txt_query” para que la inteligencia artificial tenga en cuenta la instrucción enviada por el cliente en un mensaje.
- Las “Info Vars” permiten obtener los resultados del análisis hecho por la inteligencia artificial. $txt_vision permite obtener el texto de la respuesta de la inteligencia artificial.
- Da clic en “Guardar” para aplicar la configuración del componente.
En la siguiente imagen se puede observar un ejemplo de la respuesta que obtendría un cliente si tenemos en el flujo, el uso del componente “Vision” con la nueva funcionalidad “Total Vision” configurado para hacer un análisis según la instrucción del cliente.